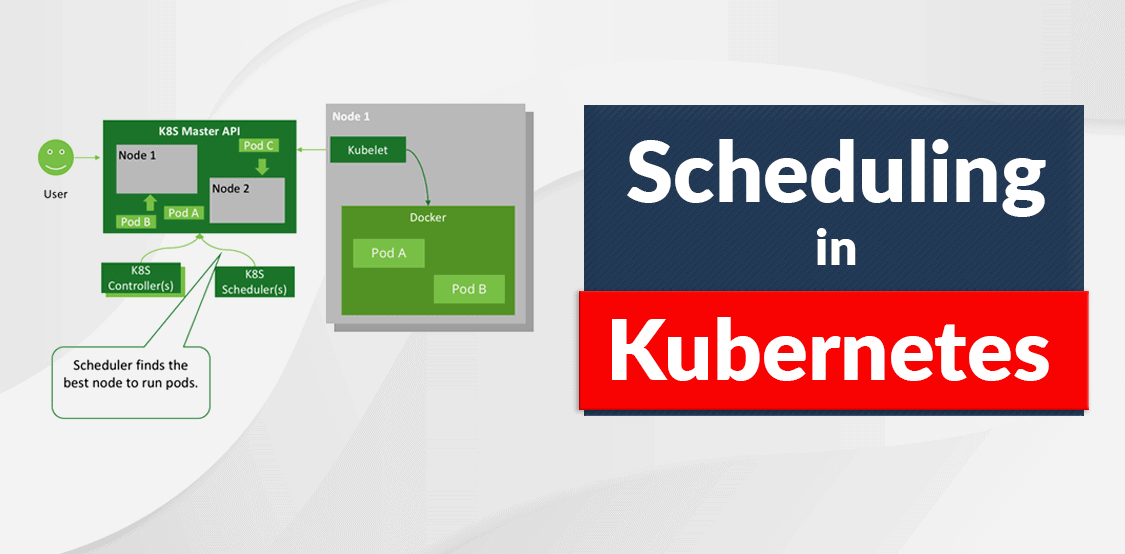
Scheduling refers to the process of ensuring that Pods get matched to the appropriate nodes within a Kubernetes cluster. This process enables users to better control where Pods end up within the cluster which in turn helps to effectively manage workloads and the underlying resources. In this post, we will explore different methods available with K8s to control the pod scheduling behavior.
What’s the need for controlling the scheduling process?
While Kubernetes will mostly manage the scheduling, there may be instances where users need to schedule pods for specific nodes. This situation is most prevalent during a K8’s deployment, where Pods need to be deployed in various nodes. Besides, controlling the scheduling process allows users to deploy Pods in matching nodes with special hardware, dedicated nodes, pods relating to each other, etc. It also enables greater control over the deployment as well as management of pods throughout their lifecycle.
Ways of Controlling Pod Scheduling
Scheduler Policy / Scheduler Profile
Modifying the default Kubernetes scheduler using a custom scheduler policy is the most basic way to customize scheduling cluster-wide. These policies can be configured with predicates and priorities defined to manage how pods are scheduled in the nodes. Scheduler policies are depreciated after Kubernetes v1.23 in favor of Scheduler profiles. Profiles provide users with greater customizability in scheduling pods, and it can be extended with scheduling plugins for further modifications. The kube-scheduler can be configured using multiple profiles, with Pods adhering to different profiles based on what is defined in the PodSpec.
Node Selector
Using Node Selectors is the simplest way to schedule a pod in a node. It uses label key-value pairs defined in a node to schedule the pod matching the defined label in the node. This is done through the nodeSelector field in the PodSpec where users can specify a map of key-value pairs. If the key-value pairs defined in the pod specification match the labels in the node, the pod will get scheduled in that node. While users can specify multiple selectors, in general, it’s recommended to use nodeSelector with a single label match due to its simplicity.
Pod Affinity / Anti-Affinity
Pod affinity and anti-affinity allow users to restrict where pods can be scheduled based on label key-value pairs on pods that are already within a node.
- Pod affinity – Pod affinity informs the scheduler to match pods to a node where the label selector of the new pod matches a label of the current pod in the node.
- Pod anti-affinity – This works to prevent pods from getting scheduled in the same node where the label selector of a new pod matches a label on a current pod.
These methods can be used to spread workloads across all nodes without getting all the pods deployed in the same node. Moreover, it reduces the risk of performance bottlenecks, service conflicts, and availability issues while helping group-related pods. These affinity rules can be created in two variants as required and preferred. The required rules must be met before a pod can be scheduled. On the other hand, preferred rules do not require a strict matching. However, the scheduler will try to enforce the rule if it matches. When defining affinity, users can configure conditions for the match expression with logical operators defined in the operator field to further customize these rules.
Node Affinity
Node affinity is similar in concept to nodeSelector where users can target specific nodes to schedule pods. Unlike node selector which uses labels, here, users can set an affinity towards a specific node or a node group using affinity rules. These rules also come with required and preferred types and operator support for further customization. Furthermore, they are defined within the PodSpec.
Taints and Tolerations
Taints and tolerations allow users to repel pods from getting scheduled to a node. Taints are applied to nodes while tolerations are configured on the pod manifest. The pod will get repelled from the node which has the taint configured if there is no matching toleration configured.
A taint consists of a key and a value with a taint effect that determines the behavior of the scheduling process. These effects are predetermined in Kubernetes and cannot be modified by users.
Tolerations supports two operators as Exist and Equal. Exist will match any node where the defined key is present, regardless of the key value. At the same time, Equal ensures that the key and the value defined in the toleration exactly match with the taint in the node. Users can define multiple taints and tolerations to further extend the functionality. Additionally, Taints can be used to control the eviction behavior of pods using the NoExecute effect. They can also be used in combination with node affinity to create dedicated nodes for special use cases.
Conclusion
Controlling Scheduling in Kubernetes provides users with the freedom to determine where to match Pods within the cluster nodes. In any K8s environment, fine-grained control over the scheduling process is one of the key aspects to proper optimization of cluster resources and better overall management of the cluster.