As a comprehensive containerized application builder, Kubernetes has risen through the ranks to establish itself as one of the must-have tools in a developer’s toolkit. With nearly 100,000 total commits to date in the Kubernetes Github repository and a system that’s able to maintain clusters with up to 5,000 nodes in any given environment, this is the perfect platform for those looking to create complex applications.
However, to a beginner in this system, Kubernetes often poses a steep learning curve. The first part of this learning process is moving through the differences between Kubernetes containers, nodes, and pods. These are the backbone of this ecosystem, with each being interconnected, by providing a different role in the wider scope of the platform.
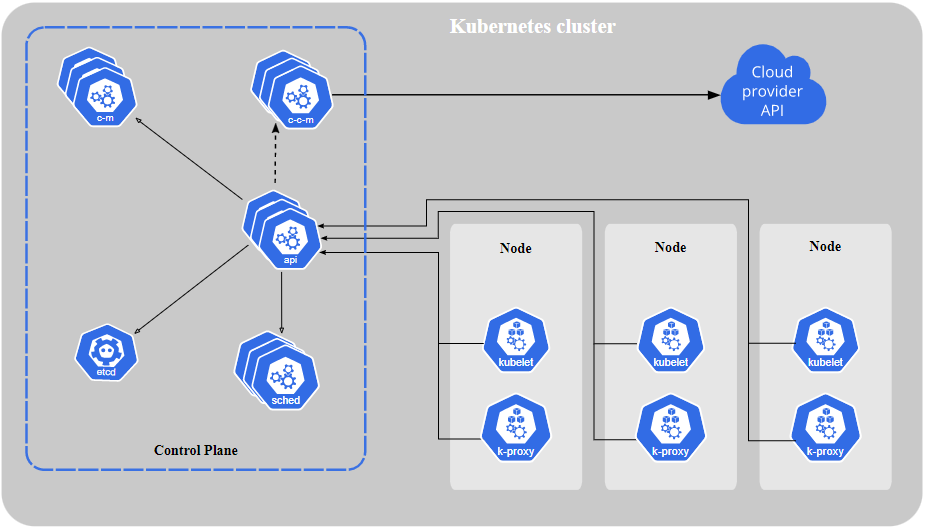
What are Kubernetes Nodes?
Within a Kubernetes ecosystem, there are three main terms that you’ll need to learn if you want to rapidly interact with this system and begin to build. These terms are:
- Containers – Containers are a virtualized operating system, isolating a specific function of an application and deploying it within a Kubernetes ecosystem. With a container image and a container engine, the container can run applications within a container, isolating it from the other running features while equally allowing it to inform and work within the wider ecosystem.
- Pods – A pod represents either a singular or a group of different containers. Equally, a pod can refer to any of the resources that those containers use, like networking cluster IP addresses, information about all of the different containers, and shared storage capabilities.
- Nodes – Nodes are the structure that host pods within the Kubernetes ecosystem. Typically, a node is an either physical or virtual space in which Kubernetes can schedule different pods and put them to work. They mostly cover certain functions, like communicating between the Pods and the containers that are currently running within your system. Equally, they can be a container runtime, which will be responsible for directly searching through registries, finding the correct file, and then running it.
Kubernetes nodes are often the most complicated of the three main types, as they contain everything else inside them. Containerized applications are stored within pods, which are in turn stored within a node. This node can then be activated via sublet or docker commands. Due to this, if you want to troubleshoot a pod and get more information about it, you will have to resort to the following commands:
- List all resources – kubectl get
- Gather all information about a specific resource – kubectl describe
- Collect and print logs from a container within a pod on that node – kubectl logs
- Complete a command on a container within a pod – kubectl exec
Quite simply, a node is a collection of all the resources that pods need to run correctly, with nodes acting as the host of either one or man pods.
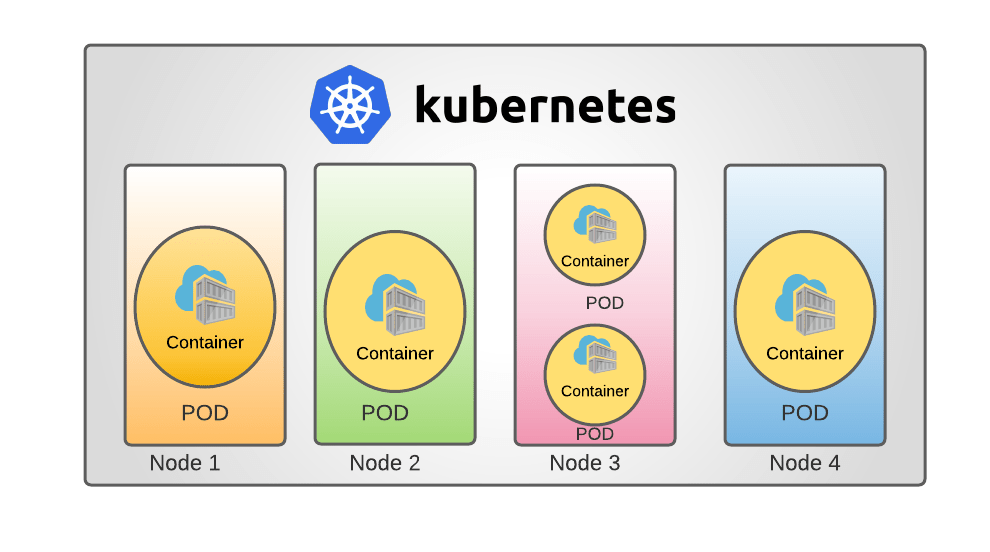
How Many Kubernetes Nodes Should You Use In A Singular Cluster?
A core part of understanding how Kubernetes nodes work is to move through basic principles of how they are constructed, how they consume resources, and how they work within a general environment. In order to properly assess how many nodes you should use in a cluster, there are three main areas you should assess:
- Availability Strategy – Due to the flexibility of the Kubernetes environment, with modifications on a cluster, container, or pod level being easily enacted, you can rely on some high-availability strategies to ensure that your pods don’t reach their point of failure. Even without these strategies, each cluster should have at least two master nodes that define the point of failure, as well as at least 12 worker nodes that are continually running.
- Strain – One of the main metrics you should be looking at when assigning nodes to a cluster is how much strain you’re placing on the cluster as a whole. Some nodes offer additional resources, such as graphical processing units or high-speed storage. Typically, you should have no more than 20% of computing resources designated to this, which will then allow for general fluctuations with defined peaks and troughs. The general rule is that the more nodes you add, the more computing and memory-based resources are also added to the cluster, allowing you to run higher tasks with a higher workload.
- Machine – The amount of strain a system can handle is directly related to the number of machines that there are supporting your environment. These come in two formats: virtual machines or bare metal hosting. While bare-metal machines are harder to come by, VMs (cloud-based plugins like Amazon EC2) are all virtual and can be added whenever. If you add more physical or virtual machines to the system, then you’ll be adding more nodes to a cluster.
Depending on the current strain that’s placed on your system and how your system is managed, you should change the total amount of nodes that you give to each cluster.
Final Thoughts
As enterprises continue to shift to using public cloud services, the use of Kubernetes in modern business is only becoming more common. One of the main reasons for the popularity of this developer playground and ecosystem is because of the fantastic multi-level containerized structures.
With nodes at the forefront of this, giving power to specific containerized application features, developers have been able to construct intricate systems, with Kubernetes now becoming one of the de facto computer control panels for both on-premise and cloud-native applications.
Over the coming years, with the movement to the cloud only further accelerating, we’re likely to see the use of Kubernetes nodes becoming even more popular, with these unique and powerful components allowing for rapid development.