Have you ever wondered how Amazon or Netflix managed to read your thoughts and recommend listings to your taste? To get a good recommendation is a valuable option that users can enjoy regardless of the service they visit. You might be willing to choose a flight, movie or product but the lack of ideas may stand in the way. In this sense, a recommendation system (RS) is a great solution for both parties – seekers and offerers. And now, there is a bunch of opportunities to make these systems powerful and efficient.
What is a recommendation system?
These services leverage fine spun algorithms built with artificial intelligence techniques such as machine learning (ML) to recommend you products and movies that you’re bound to like. In other words, at the heart of these recommendation systems lies an ML-based algorithm that analyzes data related to users. As a result, your purchase history, some personal information (location, sex, age, etc.), previous searches, favorites and other relevant data participate in shaping recommendations for you.
The most popular examples of recommendation systems and how they work
It’s worth mentioning that not only e-commerce platforms benefit from recommendation systems but also social networks, traffic navigation apps, search engines, streaming services, and other websites. Let’s look through the most popular examples to get at how they work.
- Youtube
With so many files to watch on YouTube, sometimes it may be a challenge to choose one. Fortunately, this renowned streaming service has a recommendation engine to help its users. All recommendations base on videos, genres, topics, and authors that are in your watch history. For example, you enjoyed some car building blogger in the past. YouTube considers this experience and recommends similar videos. The more you watch, the better recommendations you get. Users without YouTube watching experience get non personalized recommendations based on what other users of a particular region prefer.

The biggest global social network is not limited to one recommended system. Different sections of the website like News, Friends, Marketplace, and others apply different machine learning algorithms. At the same time, Facebook sticks to the idea that similar tastes make way for more accurate recommendations. For example, if several of your friends share a common contact among themselves, this contact will be introduced soon to you as a possible friend as well.
- Amazon
Due to recommendation algorithms, each customer of this gigantic e-commerce platform company gets in a sort of a customized store with a narrow set of listings. Recommendations consist of a mixture of filters by ratings, purchase history, type and scope of products, customer interests, etc. Besides, in the “Your recommendations” tab, customers can learn reasons for a particular listing recommendation.

What technology powers them?
The technology to power a recommendation system should be suitable for building machine learning algorithms. Developers mostly use programming languages like Python and R to work in this field. There is also a bunch of libraries including Apache Mahout (ML library implemented in Java with a package of collaborative filtering algorithms), MLlib (Apache Spark’s scalable library with a set of ML algorithms) and many others to cover AI and ML needs. Though the mentioned tools are widespread in the developer community, each experienced AI consulting company has its own toolbox for creating powerful recommendation systems.
What’s needed to build a recommendation system?
Let’s close the hood and get inside the interior to understand how recommendation systems work. Before we can engage ML algorithms to analyze data and provide a substantive recommendation to a user, the system needs to perform the four data processing actions – collection, storage, filtering, and improvement.
- Data collection
There are two ways to collect data within a recommendation system. The first one deals with the implicit behavior of users. It requires no additional user’s actions and is based on a history of user activities such as search/purchase log, clicks, etc. A good example of implicit data is a user’s order history on Amazon. The second way is an explicit data collection, which stipulates a user’s intentional action like rating or reviewing. When you give your assessment to some listings, e.g., video ratings on Netflix, you provide explicit data for the recommendation engine.
- Data storage
The recommendation accuracy directly depends on the amount of available data. One way or another, you should be prepared to deal with Big Data. The type of storage and the type of data are interdependent. The best option for storing explicit information is a scalable and managed database. Implicit data is less picky, and standard SQL or NoSQL DBs are applicable depending on what information you are going to store. In some cases, even object-based storage can be used.
- Data analysis
Before we can filter data to create an accurate recommendation, the information needs to be analyzed for timeliness. That means how fast the user has to see the recommendation. Real-time systems process data almost immediately. Systems with near-real-time analysis, which you can observe at most e-commerce websites including Amazon, process data a bit slower but during the same browsing session. Batch analysis foresees no rush and is relevant for periodical recommendations offered in follow-up emails. Now, we can move on to the heart of a recommendation engine.

- Data filtering
This process is headed by machine learning algorithms, which pick up the relevant information to shape recommendations to users. Data is being filtered according to numerous parameters including user rating, similar or corresponding listings, user’s likes, etc. In that context, recommendation systems leverage different algorithms that we’ll describe below.
Basic algorithms the recommendation engines use
Traditionally, there are three types of ML-based filter types the recommendation engines use. These include content-based, collaborative, and hybrid filtering algorithms. Let’s take a look at each of them in details.

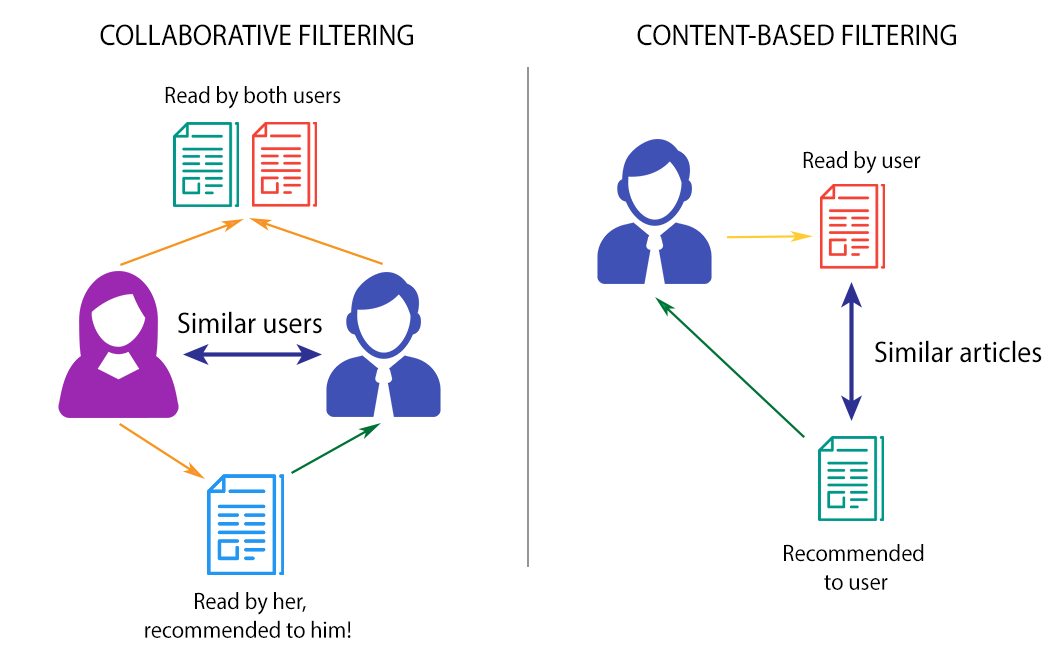
- Content Based Filtering
Let’s say you’ve liked some fantasy movie during your last visit to a streaming website. Then, the algorithm will build its recommendation on such parameters as a genre, movie director, and even cast. Content-based filtering relies on the rating a user made in the past. The effectiveness of this type of algorithm depends on descriptive data. In other words, listings should have an extensive description, and a user profile should be well organized to enable accurate recommendation.
- Collaborative filtering
Algorithms in collaborative filtering make a comparison of different users’ preferences. A recommendation is made according to matches found between them. For example, you like listings No. 1, 2, 3, and 4, while another user likes the same listings plus No.5. According to algorithms, the listing No.5 will be advised to you because there are many similarities between your and another user’s preferences. Collaborative filtering stipulates techniques that base not only on similarity score between users but also between listings. Thus, in a group of three users with relevant interests, a particular listing, which two users like, will be recommended to the third user.
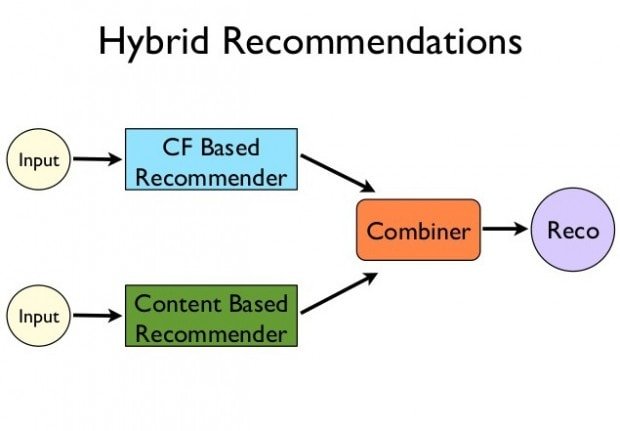
- Hybrid filtering
Hybrid always means a combination of something. In our case, hybrid filtering algorithms combine collaborative and content-based techniques. This approach allows you to merge different filtering options to achieve the maximum output. It is especially relevant when one approach is not applicable. For example, a new user has no purchase or rate history which means that content-based filtering is irrelevant. Hence, collaborative filtering techniques will be employed to make recommendations.
What are the best practices for implementing recommendation systems on websites?
Our goal is to get the most out of a recommendation system. For this reason, it is essential to follow specific practices when implementing machine learning algorithms on your website.
- Ratings
Rating aggregation is a vital component of any recommendation engine and deserves particular attention. This information provides more data about user preferences than any collaborative-based predictions. Hence, if you still have no rating for your listings, it is time to turn over.

- Meaningful description
Content-based filtering algorithms work better if rich metadata is available for your listings. The more meaningful description you store, the more accurate recommendation is expected within your system.
- Recommendation strategy
A well-tailored strategy should underlie your endeavors to create a powerful recommendation system. You should elaborate on all relevant things like recommendation timeliness, types of ML filtering algorithms, recommendations to new users who have no historical data y , and others to make your strategy solid and flexible.